Component Tests
A discussion of test types vs where they should be applied.
Different types of testing are often drawn as a pyramid:
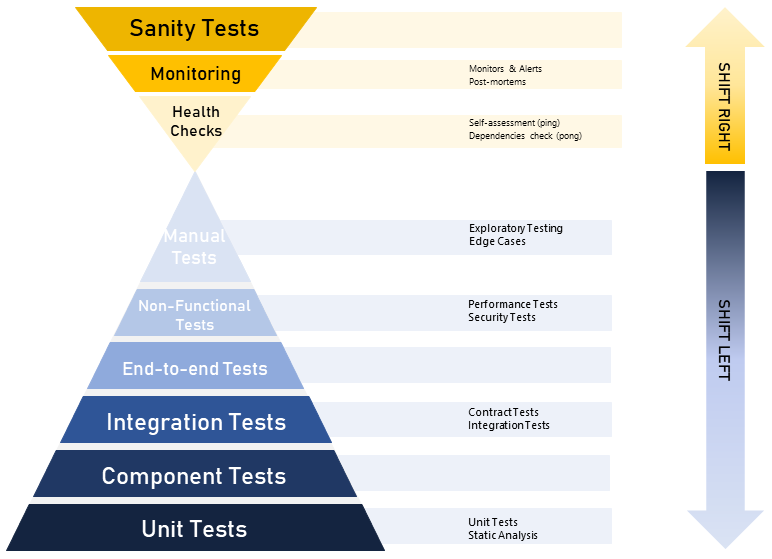
- Unit Tests provide engineers with confidence their “units” of code (i.e. functions) behave as expected, and help them find the precise cause of defects. They will run as part of validating any code change.
- Component Tests check that the application components work as expected when built and configured with mocked dependencies (e.g. a message queue, a database, a mocked API dependency, etc).
- Non-Functional Benchmarks benchmark areas such as performance, capacity or security against a reference infrastructure. Their primary aim is to signal when any of these characteristics change significantly so further checks can be performed.
- Integration Tests check the application works as expected with infrastructure in a particular environment. For example for an application deployed within AWS and on-premise, an integration test would check its functionality in one of these environments.
- End-to-End Tests check a subset of critical business flows work as expected in an environment as close to production as possible (e.g. mock as little as possible).
- Non-Functional Tests check areas such as performance, capacity, resilience and security concerns to reduce the risk of operational failures. These are often executed in a variety of environments and not necessarily all on each release.
- Manual Tests are performed to investigate new functionality, learn more about the system under test and improve our automated test coverage. They can also be used to cover areas that are hard to automate test coverage of.
- Healthchecks are commonly provided by applications themselves as a way of asserting whether they perceive themselves to be operating correctly. These can be checked on all environments including in production.
- Monitoring & Sanity Checks are the subset of tests and metrics that are used to ensure your production deployment is working as expected.
Who Runs What?
If a single team make all the code changes and are operationally responsible for any deployments, that team are responsible for all types of testing.
However, in an inner source model multiple teams make code changes, and each team can be operationally responsible for separate deployments in different environments. This situation is more complex and it is useful to separate test types into two categories:
- Reference Tests
- Deployment Tests
A single set of Reference Tests are maintained between all teams and these tests must run and pass before a code change is accepted. These tests must run in an environment where the results and logs are visible to all teams (usually GitHub Action workflows). These tests include:
- Unit Tests
- Component Tests
- Non-Functional Benchmarks
In contrast Deployment Tests are specific to the requirements of an individual deployment. While some collaboration and shared test scripts may occur between teams for such tests this may not always be desireable. These tests are usually run on team-specific infrastructure and the results are not usually immediately visible to other teams. These tests include:
- Integration Tests
- End-to-End Tests
- Non-Functional Tests
- Manual Tests
- Monitoring & Sanity Checks